

Claude 3.5 Sonnet vs GPT 4o: A Real Comparison With Actual Numbers
Claude 3.5 Sonnet vs GPT 4o: A Real Comparison With Actual Numbers
The problem with most articles comparing AI systems is that they do not provide any facts but state who wins based on their impression. They are leaving you with no more clarity about your choice than before. This one works differently.
Within weeks of each other’s debut in the middle of 2024, Claude 3.5 Sonnet and GPT-4o emerged as the two most popular AI models among developers, authors, and businesses. They were real rivals at the cutting edge of AI’s capabilities. To fully compare them, one must examine benchmark results, comprehend the practical implications of those scores, and be forthright about the shortcomings of each model.
A note upfront: both models have since been superseded. Claude 3.5 Sonnet by Claude Sonnet 4 and beyond, and GPT-4o by GPT-5 and its variants. But understanding this generation’s tradeoffs still matters, because many teams are running these models in production today, and the strengths that defined them haven’t fundamentally changed.
What the Benchmarks Actually Say
Any honest comparison starts here. Here’s what the official evaluations showed when these models were tested head-to-head:
Graduate-Level Reasoning (GPQA Diamond): Claude 3.5 Sonnet leads with a 59.4% score on 0-shot CoT GPQA, while GPT-4o has a 53.6% score. This benchmark tests the ability to handle genuinely hard academic reasoning. This type of multi-step, detailed examination distinguishes real comprehension from merely matching patterns on the surface. At the graduate level, a 5.8 percentage point difference is significant.
Math Problem-Solving (MATH Benchmark): GPT-4o leads with a 76.6% score on 0-shot CoT, while Claude 3.5 Sonnet has a 71.1% score. GPT-4o has a real edge on structured mathematical computation. If your work involves heavy numerical modeling, statistical analysis, or applied mathematics, this gap matters.
Coding (HumanEval): On HumanEval, Claude 3.5 Sonnet has a 92.0% success rate, compared to 90.2% for GPT-4o. Both are formidable, but Claude’s advantage goes beyond standards. Claude produces “nearly bug-free code on the first try,” according to seasoned programmers, whereas GPT-4o frequently needs several iterations to produce comparable results. Claude’s code has simpler implementation patterns, more deliberate variable naming, and improved structure.
Multilingual Math (MGSM): At 91.6%, Claude 3.5 Sonnet scored the highest in Multilingual Math, followed by Claude 3 Opus at 90.7%. This is a big benefit for multilingual teams.
Speed and Latency: GPT-4o has a definite, steady advantage in this situation. GPT-4o has an average latency of 24% faster, an average time to first token of 2x faster (0.56s vs. 1.23s), and an average output speed of about 2x faster than Claude 3.5 Sonnet. Real-time applications, customer-interacting chatbots, and high-volume API pipelines all exhibit this difference.
Overall, the benchmarks reveal that Claude outperforms GPT-4o in terms of reasoning depth and coding quality, while GPT-4o outperforms them in terms of speed and pure mathematics. However, the difference between the two is not as great as each side’s marketing claims.
The Multimodal Question
One of the most common claims you’ll read is that GPT-4o is the multimodal model and Claude is text-only. This is outdated and partially false.
GPT-4o does have genuine advantages in multimodal breadth. It handles audio natively, processes video, and supports voice interaction without needing external speech engines. If your workflow involves real-time voice, these are meaningful differences.
But Claude 3.5 Sonnet is not text-only. Claude 3.5 Sonnet has higher performance than GPT-4o in most vision-understanding benchmarks, outperforming it in MathVista, AI2D, Chart Q&A, and Document Visual Q&A. In other words, for visual tasks that involve documents, charts, scientific diagrams, and structured data. Exactly the kind of visual input professionals actually use, Claude performs better.
The accurate framing is this: GPT-4o has wider multimodal inputs (especially audio and video). Claude has a stronger visual comprehension of document-type images. They’re different multimodal strengths, not a multimodal vs. text-only divide.

Writing Quality (Claude’s Advantage Is Most Felt)
This is the area where benchmark numbers tell you the least, and user experience tells you the most.
Claude sounds more natural than OpenAI’s GPT series, which still tends to feel more generic. ChatGPT completes tasks based on your prompt but doesn’t think particularly strategically or offer up a variety of options unprompted. Claude does. And because getting solid content from an LLM requires plenty of back-and-forth iteration, Claude’s more collaborative approach often leads to better creative outcomes.
This matters more than it sounds. The AI writing that gets noticed by readers, that doesn’t immediately announce itself as machine-generated, is the kind Claude consistently produces. The “aggressively bulleted, over-formatted, boilerplate” output that has become synonymous with GPT-4o is a real limitation for anyone writing for a human audience.

While GPT-4o can create coherent content in a range of forms, Claude 3.5 Sonnet has an advantage because of its reputation for creating complex, high-quality content, which makes it particularly useful for engagement and marketing.
Claude has a genuine and persistent advantage for content creators who write long-form articles, essays, documentation, or any material meant to be read by humans. GPT-4o is fine for writing functional emails, short copy, and summaries. But struggles to match Claude on pieces that require voice, judgment, and narrative flow.
Coding (A Closer Look)
Both models are genuinely good at coding. The question is, which kind of coding?
Tens of thousands of tokens from an entire legacy service can be fed into a single prompt using Claude 3.5 Sonnet. After that, it may produce a logical, detailed migration plan. GPT-4o counters with speed for teams in ChatOps channels where fixes are needed quickly, and its larger output limit helps when generating exhaustive API docs from scattered markdown files.
In practice, the coding use case splits along complexity and context length. Claude excels when tasks require holding a large codebase in mind at once, such as refactoring, documentation generation, and architectural review. It is also highly effective at writing tests for existing code. GPT-4o is faster for quick fixes, short scripts, and back-and-forth debugging sessions where iteration speed matters more than deep context.
In an internal agentic coding evaluation, Claude 3.5 Sonnet solved 64% of problems, outperforming Claude 3 Opus, which solved 38%. The jump within Anthropic’s own lineup was dramatic. And the improvement translated directly to real-world developer workflows.

Long Documents (Claude’s Most Consistent Win)
With Claude’s 200K-token window, you can process entire research papers, contracts, or massive codebases without splitting them. GPT-4o has a 128K context limit, which can still handle substantial documents. However, a single 10-K filing often exceeds 150,000 tokens, fitting within Claude’s window but requiring trimming or retrieval management with GPT-4o.
The gap isn’t just about raw token count; it’s about what the model does with the full context. Claude maintains coherence across long documents more reliably. You can ask a question about section 18 of a 90-page legal contract and get an answer that accounts for definitions established in section 3. That kind of long-range context retention is where Claude genuinely earns its reputation for document work.
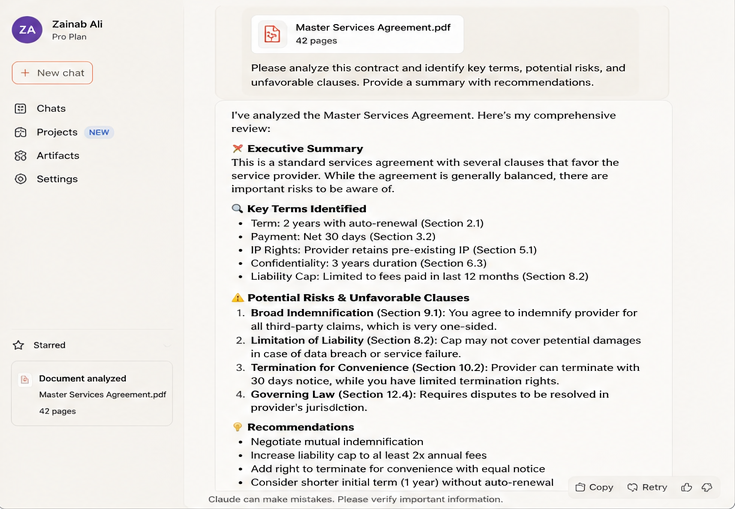
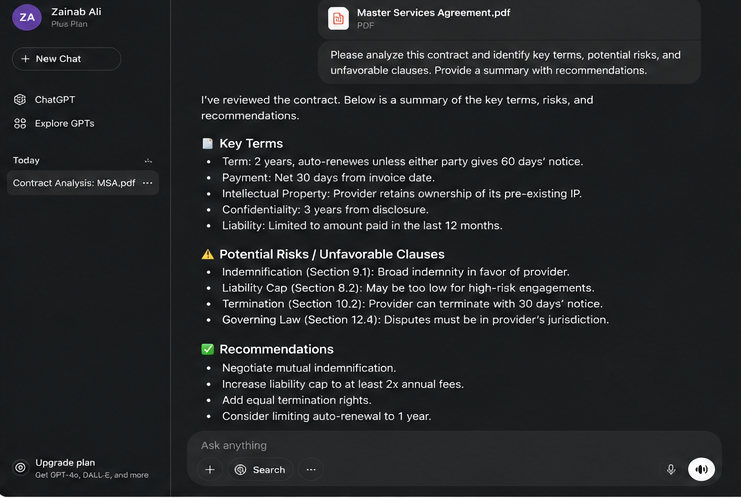
Real-world testing on legal contract analysis showed nuance here: in extracting key information from Master Services Agreements, GPT-4 outperformed Claude on 5 of 14 fields, maintained similar performance on 7, and showed degraded performance on 2. Both models achieved only 60–80% accuracy on most fields, indicating that complex data extraction still requires advanced prompting techniques regardless of model choice.
The honest takeaway: Claude handles long documents better, but neither model eliminates the need for careful prompting on genuinely complex extraction tasks.
A Practical Breakdown

Choose Claude 3.5 Sonnet when:
You worry about voice and genuineness since you are producing long-form content for human readers. When working with lengthy publications, such as technical manuals, research papers, and legal contracts, you need the model to maintain context throughout. Instead of writing quick scripts, you are working on serious coding projects that require a comprehension of a codebase. You need graduate-level reasoning and analytical depth. You’re building classification systems where overall accuracy matters more than avoiding false positives.
Choose GPT-4o when:
You need native voice or real-time audio interaction. Speed is a priority. High-volume APIs, real-time customer interfaces, or applications where first-token latency is user-facing. Your work is math-heavy, involving precise numerical computation, financial modeling, or applied statistics. You need the broadest plugin and tool ecosystem. You’re doing shorter, faster exchanges where GPT-4o’s responsiveness feels more fluid.
Pricing
At the API level, Claude 3.5 Sonnet is priced at $3 per million input tokens and $15 per million output tokens. GPT-4o’s pricing has varied but sits in a comparable range for output, with input tokens slightly higher. For consumer use, both Claude Pro and ChatGPT Plus run at $20 per month at their base tiers.
The more important pricing consideration is token efficiency in practice. Claude’s larger context window means you can accomplish more in a single API call, which can reduce costs significantly on document-heavy workflows that would otherwise require chunking and multiple calls with GPT-4o.
The Writing Quality Divide
There’s a reason developers and writers tend to converge on Claude for text-heavy work. It’s not sentiment; it’s a consistent pattern in how the two models handle ambiguity, instruction nuance, and stylistic range.
GPT-4o will give you a correct, serviceable answer to almost anything. Claude will give you a correct answer that also considers whether there’s a better framing of your question, offers alternatives you didn’t ask for but might want, and writes in a way that sounds like it came from someone thinking rather than a model completing a pattern.
It would be best for Claude to cater to those users who are concerned with complex and advanced creativity, since it has a more naturalistic writing style, advanced analysis capability, and reasoning.
GPT-4o would be more ideal for users looking for a tool that is a complete solution, from image generation with DALL-E to voice functionality and wide-ranging plugins.
No answer is wrong. These two answers just present two different products that represent two different philosophies: Anthropic is optimizing for depth, while OpenAI is optimizing for breadth
One Limitation Worth Naming Honestly
Claude can be overly cautious. It occasionally declines requests that pose no genuine risk, adds caveats where none are needed, and hedges in contexts where a direct answer would serve better. This is a real friction point for developers building pipelines where Claude’s safety filters trigger on legitimate content.
GPT-4o has its own version of this problem, but Claude’s is more noticeable in edge cases. Anthropic has reduced this tendency significantly across model generations, but if you’re building applications that push against content policy edges, you’ll encounter it.
The Bottom Line
Claude 3.5 Sonnet is the stronger model for reasoning, coding, long-document work, and writing quality. GPT-4o is the stronger model for speed, native multimodal interactions, and mathematical computation. The differences are real but not enormous; both are excellent models that will handle 90% of tasks well.
The smartest approach isn’t picking one permanently. It’s knowing which scenario calls for which tool and switching without friction. For deep work that requires the model to think, use Claude. For fast, multimodal, or math-heavy tasks, GPT-4o earns its place.
A note on model generations: As of 2026, both Claude 3.5 Sonnet and GPT-4o have been superseded by newer models. Claude Sonnet 4, Opus 4, and their successors significantly extend Claude’s capabilities. GPT-5 and its variants represent OpenAI’s current frontier. The tradeoffs described above—Claude’s depth vs GPT-4o’s speed and breadth—remain directionally consistent in newer generations, though the gap has shifted in different ways across categories.
For more guides, tips, and use cases, explore our blogs at ClaudeAIWeb.
FAQs
1. Is Claude 3.5 better than GPT-4o?
When the job involves long reports, detailed research, or anything that requires careful, compliant handling, Claude 3.5 really steps up. It keeps the context intact and delivers dependable accuracy. GPT-4o brings a different kind of strength. It’s the model you turn to when you need creativity, visuals, or hands-on coding support. Whether you’re crafting marketing content, building story ideas, or developing interactive tools, GPT-4o adds that extra spark.
2. Can ChatGPT 4o handle large PDFs?
Yes, ChatGPT-4o can process large PDFs, but it has a smaller context window than Claude. For extremely long files, Claude 3.5 handles multi-page documents more efficiently. It maintains context and accuracy, which is especially useful for legal, research, or technical document analysis.
3. Which AI is more affordable?
Claude 3.5 works on a pay-per-token system, which makes it a budget-friendly option if you regularly process large documents or datasets. ChatGPT-4o runs on a monthly subscription, which is convenient for casual use but can get pricey if you rely on it heavily every day.
4. Can I use both models together?
Yes, using both models strategically maximizes productivity. Claude 3.5 handles compliance-heavy and long-document work, while ChatGPT-4o supports creativity, coding, and multimodal projects. Teams can switch between them depending on task requirements for optimal results.
5. Which is better for startups?
Startups often benefit from Claude 3.5 due to cost-efficient pay-per-token pricing and strong long-document handling. ChatGPT-4o offers creative and coding advantages, but for budget-conscious or research-heavy startups, Claude provides better value while maintaining accuracy and reliability.





