

Why Claude 4 is the Next Big AI for US Enterprises and Creators
I’ve tested most major AI tools across real content, research, and automation workflows. Most of them impress in demos and disappoint in daily use. Claude 4 is the first model in a while that I kept returning to, not because of a launch announcement, but because it consistently handled tasks that tripped up everything else.
That experience pushed me to write this. This isn’t a feature summary you could find on Anthropic’s website. It’s a practical look at why Claude 4 is quietly becoming the default AI inside marketing teams, research departments, and regulated industries in the US. And what you need to know before deciding whether it’s right for your workflow.
| Note on transparencyClaudeAIWeb.com is an independent fan site. We are not affiliated with or sponsored by Anthropic. All opinions are based on independent testing. |
For those seeking detailed guidance, explore our Claude Sonnet 4.5 blog.

What Is Claude 4?
Claude 4 is Anthropic’s current flagship large language model (LLM). Anthropic positions it as a model built around three priorities: context retention, output accuracy, and safe decision-making in high-stakes tasks.
It builds on Claude 3.7 Sonnet, which was already a capable model for general tasks. Claude 4 noticeably reduces the kinds of errors that frustrate professionals, such as misinterpreted instructions, hallucinated facts in reports, and context loss midway through long documents.
In my testing, the difference shows up most clearly in three scenarios:
- Summarizing and cross-referencing long legal or policy documents (100+ pages)
- Writing strategic content that requires a consistent tone over multiple drafts
- Handling structured analytical tasks where accuracy matters more than creativity
Hands-on observation
I ran Claude 4 through a 90-page market research PDF and asked it to pull out key data points, identify contradictions between sections, and write an executive summary. It completed the task without losing thread—something Claude 3 Sonnet struggled with past the 50-page mark.
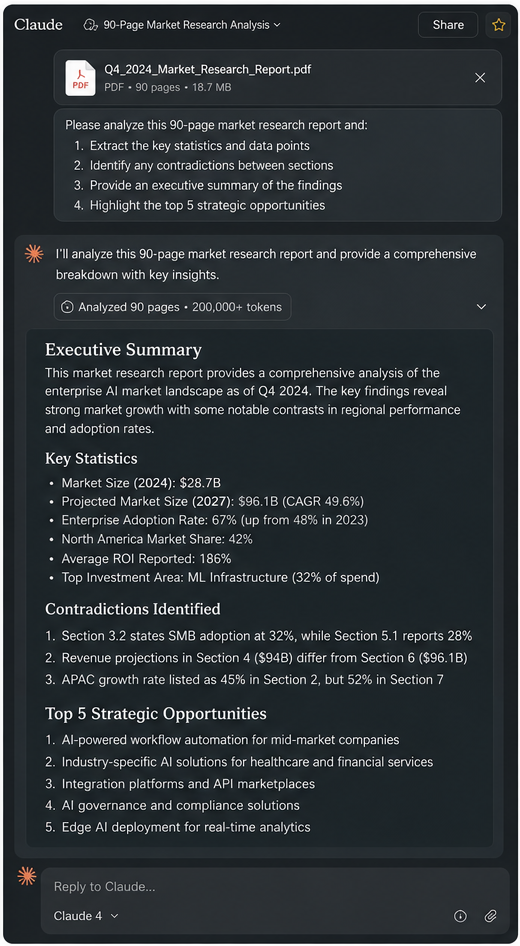
For deeper insights, see Claude Opus 4 applications.
How I Tested Claude 4
To evaluate Claude 4 beyond marketing claims and benchmark scores, I tested it across a range of real-world professional workflows over several weeks.
The testing included:
- A 90-page market research report requiring summarization, contradiction detection, and executive-level insights
- Long-form content creation, including blog articles, email sequences, and investor-facing documents
- Competitive research projects involving multiple source documents
- Multimodal analysis tasks using charts, dashboards, and visual reports
- Compliance-focused writing tasks where factual accuracy and careful language were important
Claude 4 vs. Other Claude Models
For comparison, I also ran similar prompts through ChatGPT and Gemini where appropriate. Rather than focusing solely on speed or benchmark performance, I evaluated each model based on:
- Accuracy of information
- Ability to maintain context over long conversations
- Consistency of writing quality
- Instruction-following reliability
- Handling of large documents
- Practical usefulness in professional workflows
The goal was not to determine which model wins every category. Instead, I wanted to understand where Claude 4 provides meaningful advantages and where competing tools may be a better fit.For comparison, I also ran similar prompts through ChatGPT and Gemini where appropriate. Rather than focusing solely on speed or benchmark performance, I evaluated each model based on:
- Accuracy of information
- Ability to maintain context over long conversations
- Consistency of writing quality
- Instruction-following reliability
- Handling of large documents
- Practical usefulness in professional workflows
The goal was not to determine which model wins every category. Instead, I wanted to understand where Claude 4 provides meaningful advantages and where competing tools may be a better fit.
Key Features of Claude 4
Claude 4 introduces innovations that enhance performance and user experience.
1. The 200,000-Token Context Window
Claude 4 processes up to 200,000 tokens in a single session, roughly equivalent to 500 pages of text. For most users, this means you can load an entire contract, report, or codebase and ask questions without losing context between chunks.
Most competing models lose coherence after the 50,000–100,000 token range. This alone has real ROI implications for legal teams, researchers, and content teams dealing with large reference documents.
Important caveat: long context performance degrades toward the middle of very large inputs. For tasks exceeding 150,000 tokens, I’d recommend breaking content into logical sections and processing them in sequence rather than dumping everything at once.
2. Reduced Hallucinations in Factual Tasks
Claude 4 is noticeably more conservative than earlier models when it lacks confidence. Instead of inventing plausible-sounding details, it tends to flag uncertainty or ask for clarification.
In my testing with financial and research content, this made a meaningful difference. I still recommend human review for any factual claim that will be published or acted upon, no LLM has eliminated hallucinations entirely.
3. Multimodal Input
Claude 4 can process text, images, and graphs within the same session. For marketers analyzing campaign performance dashboards, healthcare professionals reviewing research charts, or analysts working with mixed media reports, this removes the need to manually describe visual content.

4. Speed and Scalability
For high-volume tasks, drafting product descriptions, responding to support queries, and generating report variations, Claude 4 performs well at scale. It’s not the fastest model available (Claude Sonnet 4.5 beats it for raw speed), but response quality holds up better under complex instructions.
Claude 4 vs. Other Claude Models
Anthropic’s model lineup can be confusing. Here’s a practical breakdown of where each fits:
| Model | Context Window | Best For | Speed | Trade-off |
|---|---|---|---|---|
| Claude 4 | 200K tokens | Marketing, research, and regulated industries | Fast | Premium pricing |
| Claude Sonnet 4.5 | 200K tokens | High-volume tasks, advanced analytics | Fastest | Less nuanced on complex writing |
| Claude Opus 4 | 150K tokens | Enterprise analytics, deep reasoning | Moderate | Slower, higher cost |
| Claude Sonnet 4 | 100K tokens | Content drafting, everyday tasks | Medium | Shorter memory span |
If you’re using Claude for everyday writing and content drafts, Sonnet 4 is more cost-efficient. Claude 4 earns its place when you need sustained accuracy across long, complex tasks.
Claude 4 vs. ChatGPT and Gemini: Where Each Actually Wins
The honest answer is that no single model dominates every use case. Here’s how they compare in the tasks I actually tested:
| Model | Strengths | Weaknesses | Best Use Case |
|---|---|---|---|
| Claude 4 | Long context, safe outputs, nuanced writing | Premium pricing, no image generation | Marketing, enterprise research, compliance |
| ChatGPT (GPT-4o) | Speed, wide plugin ecosystem, image gen | Shorter effective context, prone to verbosity | Quick tasks, coding, image-based work |
| Gemini 2.5 Pro | Coding precision, Google Workspace integration | Creative writing less polished | Software dev, technical documentation |
| Llama 3 (open-source) | Free, self-hostable, customizable | Requires technical setup, less reliable out of box | Research, experimentation, budget builds |

My take
For coding tasks, Gemini 2.5 Pro is genuinely better. For long-form content, complex research, or any task in a regulated industry where output safety matters, Claude 4 is my default. ChatGPT remains the most versatile all-rounder if you’re only picking one tool.
Real-World Use Cases by Industry
Startups and Marketing Teams
Claude 4 excels at drafting long-form content that stays on-strategy across multiple sections. I’ve used it to write investor-facing narratives, product positioning documents, and multi-angle email sequences, and the tone remains consistent in a way that earlier models didn’t.
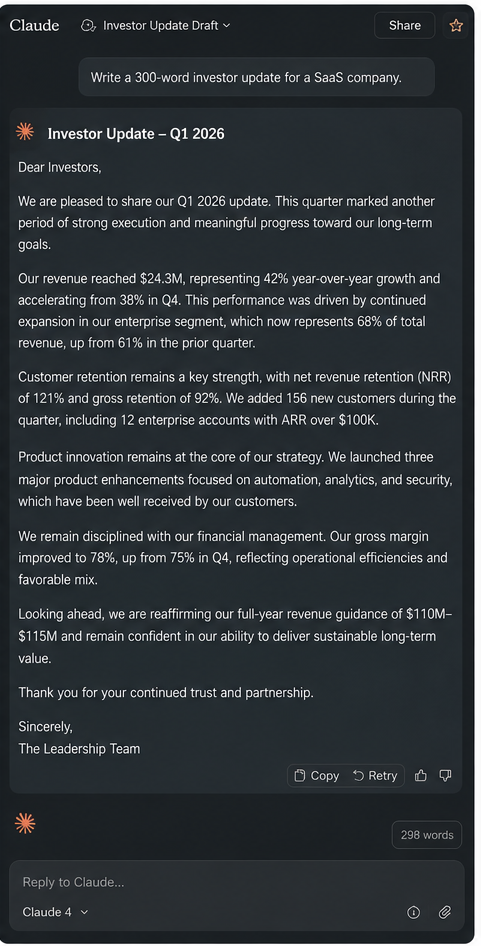
- Investor pitch narratives with a consistent voice across sections
- Competitor intelligence summaries from past research
- Full email campaign sequences (5–7 emails) with varied angles
Ecommerce
- Bulk product descriptions with unique angles per SKU
- FAQ generation from product specs or customer reviews
- Customer support response templates that handle edge cases
Healthcare and Compliance
Claude 4’s conservative output style makes it better suited than most models for healthcare and legal content. It tends to flag uncertainty rather than fill gaps with confident-sounding guesses.
- Summarizing clinical research papers
- Drafting patient-facing content with appropriate caveats
- Reviewing compliance documents for plain-language gaps
Important: Always have qualified professionals review AI-generated content in these sectors. Claude 4 reduces review time; it doesn’t eliminate the need for it.
Education
- Lesson plan generation with customizable difficulty levels
- Rubric creation aligned to learning objectives
- Personalized quiz and flashcard sets from source material
Pricing: Is It Worth It?
Claude 4 is subscription-based. Anthropic’s current tier structure (as of early 2026):
| Plan | Access | Approx. Price | Who It’s For |
|---|---|---|---|
| Free | Limited Claude access (typically Sonnet) | $0/month | Casual users, early testers |
| Claude Pro | Claude 4 access, higher message limits | $20/month | Individual professionals and creators |
| Claude Team | Team features, admin controls | $30/user/month | Small teams |
| Enterprise | API access, custom contracts | Contact Anthropic | Large organizations |
My honest take: The $20 Pro plan is worth it if you use AI for work more than 3–4 times a week. The jump from Sonnet to Claude 4 on complex tasks is real. For casual or occasional use, the free tier with Sonnet is genuinely functional.
What Claude 4 Still Gets Wrong
Any honest review needs a limitations section. Here’s where I’ve hit friction:
- No image generation: Claude 4 analyzes images but doesn’t create them. If you need image generation in your workflow, you’ll need a separate tool like Midjourney or DALL·E.
- Context degradation in the 150K+ range: performance on very long inputs is good, not flawless. For documents over ~300 pages, chunk your inputs.
- Pricing for API access: enterprise and API costs are high compared to some alternatives, especially for high-volume automation.
- Occasional over-caution: Claude 4’s safety emphasis sometimes produces hedged answers where a direct response would be more useful. You can usually fix this with a clearer, more specific prompt.
Bottom Line
Claude 4 is not the right tool for every task. If you need image generation, fast code completion, or a free option with no usage limits, other tools serve those needs better.
What does Claude 4 do well? Maintaining context across long documents, producing accurate and appropriately cautious outputs, and sustaining quality in complex writing tasks. It does better than any model I’ve tested at this price point.
For US enterprises, marketing teams, and serious creators who are tired of editing AI output that sounds confident but gets things wrong, Claude 4 is worth a proper trial. Start with the Pro tier, run it through two or three of your hardest regular tasks, and judge by the output rather than the spec sheet.
Explore more on Claude AI Web to stay updated.
FAQs
Is Claude 4 free to use?
Claude 4 is available on paid plans starting at $20/month (Claude Pro). Anthropic’s free tier gives access to a limited version of Claude (typically Sonnet), which handles everyday tasks well but does not include Claude 4’s full capabilities.
Can Claude 4 replace human workers?
No, and this framing tends to mislead. Claude 4 is a productivity tool. It reduces time spent on repetitive writing, analysis, and drafting tasks. The quality of output still depends on how well a human frames the task and reviews the result. In professional contexts, human oversight remains essential.
Is Claude Sonnet 4 better than Claude 3.7?
Yes, in most practical scenarios. Claude Sonnet 4 is faster, handles longer contexts more reliably, and produces fewer formatting errors than 3.7. For everyday writing and professional tasks, it’s a clear upgrade.
How does Claude 4 compare to GPT-4o?
Claude 4 outperforms GPT-4o on long-context tasks and produces more consistently careful outputs in compliance-sensitive or research-heavy work. GPT-4o has a broader plugin ecosystem and better native image generation. The best choice depends on your specific workflow.
Is Claude 4 safe for sensitive business data?
Anthropic does not use your conversations to train future models if you are on a paid plan, according to their privacy policy. For enterprise use, review Anthropic’s data handling terms and consider the API or Enterprise tier, which offers stronger contractual data protections. For highly sensitive data, always consult your legal or security team before using any cloud AI service.





